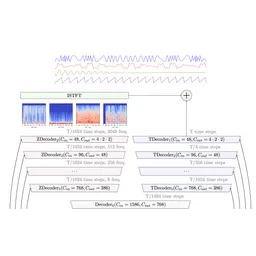
Overview
Demucs is a music source separation model developed by Facebook Research, designed to isolate individual instrument tracks (drums, bass, vocals, etc.) from a complete music recording. It utilizes a U-Net convolutional architecture inspired by Wave-U-Net. The v4 version, Hybrid Transformer Demucs (HT Demucs), uses a hybrid spectrogram/waveform separation approach, incorporating Transformer Encoders for self and cross-domain attention. This architecture allows the model to achieve state-of-the-art results in separating audio sources. The model's trained on the MUSDB HQ dataset and an extra training dataset of 800 songs. Demucs can be used to create karaoke tracks, isolate instrumental parts for remixing, or improve audio quality by removing unwanted sounds. It's implemented in Python and PyTorch, and can be installed via pip or conda.