Sourcify
Effortlessly find and manage open-source dependencies for your projects.
Development
Freemium
From $99/mo
Smart Contract Verification
Dependency Management
Security Auditing
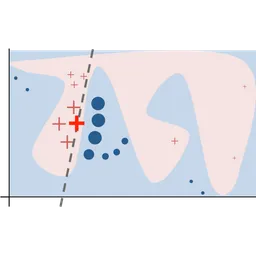
Enable trust and transparency in black-box models through local interpretable surrogate explanations.

LIME (Local Interpretable Model-agnostic Explanations) is a foundational open-source framework in the field of Explainable AI (XAI) that allows developers and data scientists to explain the predictions of any machine learning classifier or regressor. By treating models as black boxes, LIME perturbs input data points and observes the resulting changes in output to learn a local, interpretable linear model around a specific instance. In the 2026 AI market, LIME remains a critical tool for regulatory compliance (such as GDPR's 'right to explanation') and model debugging. It excels in high-stakes environments like healthcare and fintech, where understanding why a model made a specific decision—such as rejecting a loan or flagging a medical anomaly—is as important as the prediction itself. The library supports a wide array of data types including tabular, text, and image data, and remains model-agnostic, meaning it can interface with Scikit-learn, TensorFlow, PyTorch, and proprietary LLMs. Its 'Submodular Pick' feature further allows for a representative overview of the model's global behavior by selecting a diverse set of local explanations, bridging the gap between local and global interpretability.
LIME (Local Interpretable Model-agnostic Explanations) is a foundational open-source framework in the field of Explainable AI (XAI) that allows developers and data scientists to explain the predictions of any machine learning classifier or regressor.
Explore all tools that specialize in feature importance analysis. This domain focus ensures LIME (Local Interpretable Model-agnostic Explanations) delivers optimized results for this specific requirement.
Uses a perturbation-based approach to probe models without requiring access to internal weights or gradients.
Algorithms that select a set of representative instances with their explanations to provide a non-redundant global view.
Uses super-pixels to highlight specific regions of an image that contributed most to a classification.
Employs a bag-of-words approach on perturbed text samples to identify words with high predictive weight.
Utilizes K-LASSO to select the most important features in the local surrogate model.
Automatically handles categorical features in tabular data by perturbing based on the distribution of the training set.
Allows users to define custom distance metrics (kernels) to determine the size of the 'neighborhood' for explanations.
Install the library via pip: pip install lime
Import the relevant explainer (LimeTabularExplainer, LimeTextExplainer, or LimeImageExplainer)
Prepare your training data and ensure your black-box model has a 'predict_proba' or equivalent function
Initialize the explainer with your training set and feature names
Select a specific instance or row from your test set that requires explanation
Generate an explanation by passing the instance and the model's prediction function to the explainer
Visualize the explanation using show_in_notebook() or as_list()
Filter features based on weight thresholds to identify key drivers of the prediction
Perform a 'Submodular Pick' to validate the explanation's consistency across multiple instances
Export the explanation as HTML or JSON for audit logging or frontend integration
All Set
Ready to go
Verified feedback from other users.
"Widely praised for its model-agnostic nature and ease of use, though some users note that explanations can vary slightly between runs due to random sampling."
Post questions, share tips, and help other users.
Effortlessly find and manage open-source dependencies for your projects.

End-to-end typesafe APIs made easy.

Page speed monitoring with Lighthouse, focusing on user experience metrics and data visualization.

Topcoder is a pioneer in crowdsourcing, connecting businesses with a global talent network to solve technical challenges.

Explore millions of Discord Bots and Discord Apps.

Build internal tools 10x faster with an open-source low-code platform.

Open-source RAG evaluation tool for assessing accuracy, context quality, and latency of RAG systems.
AI-powered synthetic data generation for software and AI development, ensuring compliance and accelerating engineering velocity.