
Csound
A free and open-source audio programming language for sound and music computing.
21d ago
Best for General AIHas API
PricingFree
Free
Audio Synthesis
Sound Design
Algorithmic Composition
Easily train a good VC model with voice data in <= 10 mins!
Easily train a good VC model with voice data in <= 10 mins!
Retrieval-based Voice Conversion WebUI is an open-source framework that facilitates voice conversion using retrieval-based techniques. It leverages VITS and allows users to train voice conversion models with limited voice data (<= 10 minutes). The system operates by replacing input source features with training set features using top1 retrieval, mitigating voice leakage. It offers a user-friendly web interface built with Gradio. Key features include fast training on modest hardware, model merging for voice alteration, UVR5 model integration for vocal and instrumental separation, and RMVPE for advanced pitch extraction to eliminate silent sounds. A-card and I-card acceleration are supported.
Easily train a good VC model with voice data in <= 10 mins!
Quick visual proof for Retrieval-based Voice Conversion WebUI. Helps non-technical users understand the interface faster.

Retrieval-based Voice Conversion WebUI is an open-source framework that facilitates voice conversion using retrieval-based techniques.
Explore all tools that specialize in synthesize speech. This domain focus ensures Retrieval-based Voice Conversion WebUI delivers optimized results for this specific requirement.
Explore all tools that specialize in voice cloning. This domain focus ensures Retrieval-based Voice Conversion WebUI delivers optimized results for this specific requirement.
Open side-by-side comparison first, then move to deeper alternatives guidance.
Replaces input source features with training set features using top1 retrieval algorithm, minimizing voice timbre leakage.
Allows merging of different models to modify voice characteristics using CKPT processing.
Integrates with UVR5 model for quick separation of vocals and instrumentals.
Utilizes RMVPE algorithm for advanced pitch extraction, addressing issues related to silent sounds.
Supports acceleration using AMD and Intel GPUs for faster training and inference.
Install Python (>=3.8).
Install PyTorch with CUDA support: `pip install torch torchvision torchaudio`
Install dependencies: `pip install -r requirements.txt`
Download pre-trained models (hubert_base.pt, pretrained models, uvr5_weights) from Hugging Face.
Install FFmpeg.
Download and place RMVPE pitch extraction model.
Start the WebUI: `python infer-web.py`
All Set
Ready to go
Verified feedback from other users.
“Users praise the tool's ease of use and quality of voice conversion, though some note occasional issues with hardware compatibility.”
No reviews yet. Be the first to rate this tool.
A free and open-source audio programming language for sound and music computing.

The best choice for designing top-quality, dancefloor-crushing bangers.
Singing Voice Conversion via diffusion model.
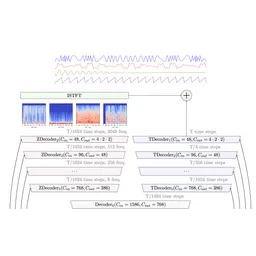
State-of-the-art music source separation model capable of separating drums, bass, and vocals from the rest of the accompaniment.
Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech.

High-fidelity AI voice cloning and speech synthesis for entertainment and enterprise.

